Is You Agent Safe?
The gap between a working POC and a production-ready agent is where most teams get burned.
Your demo works.
The agent reads inputs, calls the right tools, returns clean outputs. You show the team. Everyone's impressed. You ship it.
Three days later something goes wrong.
Maybe it silently fails on a bad input and produces garbage downstream. Maybe it calls a tool twice because a retry had no idempotency check. Maybe it runs an operation it should have asked permission for first.
This is not a model problem. The model was fine. The gap was everything built around it.
I learned this while integrating AI agents into a real production backend. The POC was solid. The move to production revealed a list of things that "worked in testing" but had no business being in a live system.
None of it was exotic. All of it was preventable.
The POC Lies to You
A POC runs on clean inputs, a controlled environment, and your own supervision. You are the guardrail. You watch every output. If something looks off, you catch it.
Production removes you from that loop entirely.
Research on multi-agent failures shows something counterintuitive: failures often can't be attributed to the model. The same model in a single-agent setup frequently outperforms the multi-agent version. The orchestration and surrounding design is where most production failures originate — not the LLM.
The other thing nobody tells you: agents don't always fail loudly.
A broken API returns a 500. An agent can misunderstand an instruction on step two, propagate that silently across twenty downstream steps, return a confident and well-formatted output, and be completely wrong. You discover it in the damage report.
Silent wrong outputs are worse than crashes. A crash you can detect.
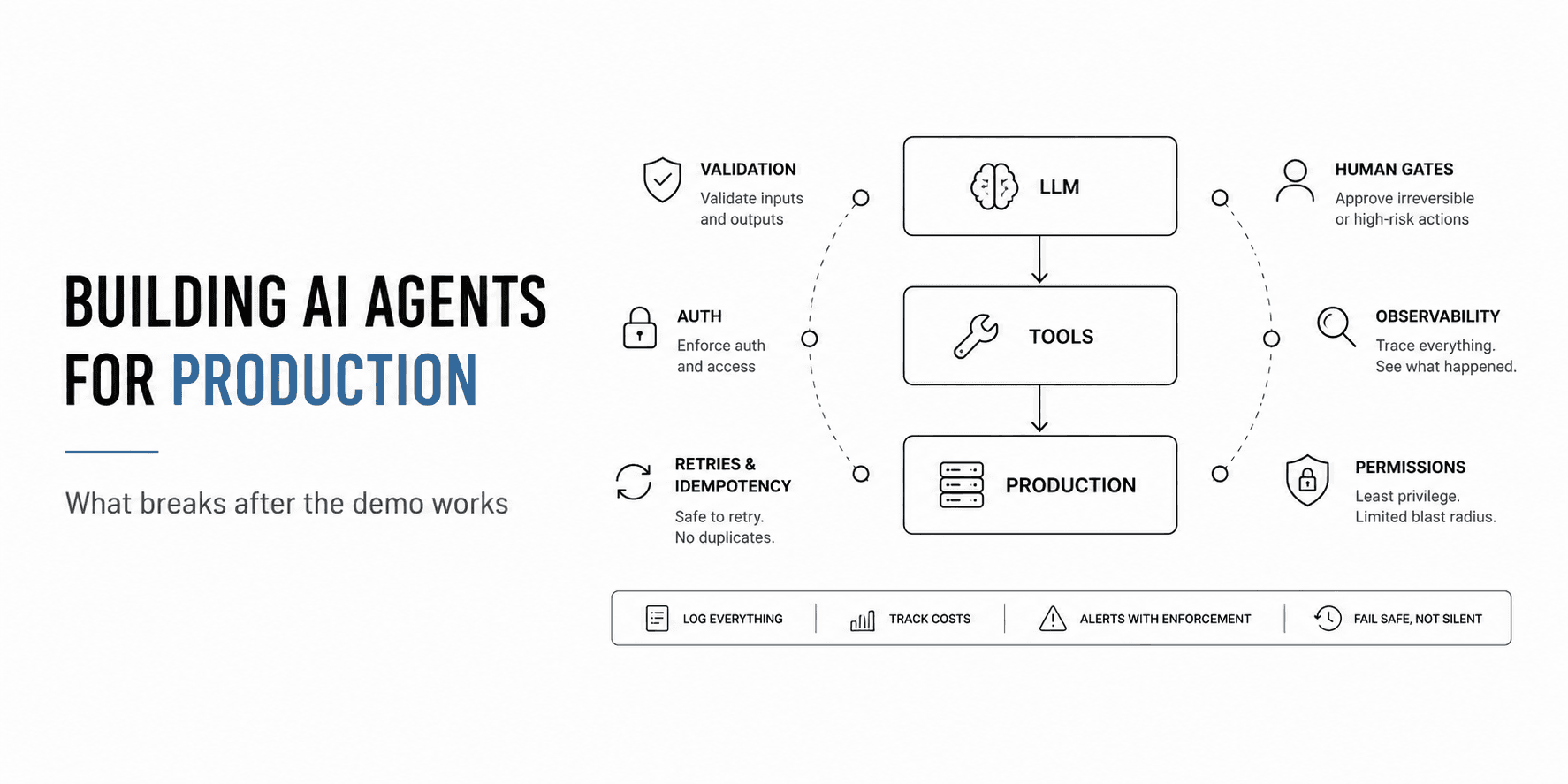
Standard 1: Tools Need Contracts, Not Just Code
In a POC, you write a function, give it a rough description, and the model figures out how to use it.
That breaks in production.
Vague tool descriptions produce incorrect tool selection. The agent picks the wrong tool, passes wrong parameters, and you get a hallucination instead of a real error.
Every tool in production needs:
- A strict input schema the model cannot violate
- A consistent response envelope for both success and failure
- A description that includes what the tool does, when to use it, and its side effects
- Explicit error cases — not just the happy path
Amazon built thousands of agents across their org since 2025. Their fix was cross-organizational standards for tool schema and description formalization — mandatory for every builder team. Exact formats for tool signatures, input validation, output contracts, and documentation.
That's not bureaucracy. That's what keeps agents from inventing their own interpretation of your API.
Standard 2: Never Let the Model Handle Auth or Validation
This one sounds obvious. Most teams still violate it.
The model reasons well. It does not consistently enforce security rules under adversarial conditions, schema edge cases, or unexpected inputs.
Any logic that must always hold — without exception — should not live inside a prompt.
In practice:
- Input validation happens before the model sees it. Anything from an external source — a user, an API, a retrieved document — is sanitized at the layer before it enters the agent context.
- Authorization checks live in your infrastructure, not your system prompt. "Only access records belonging to the current user" is a suggestion inside a prompt. It's an enforceable rule inside your middleware.
- Output validation happens before results leave your system. If the agent is supposed to return structured data, validate the structure and business rules before handing it downstream.
The model is the reasoning layer. Everything else is your responsibility.
Standard 3: Idempotency Is Not Optional Once You Have Retries
Every real system retries failed operations. The question is what happens when an agent retries a tool call that already partially executed.
A plain CRUD app handles this cleanly — the request is idempotent by design. An agent that drops a tool call mid-retry can believe it already completed an action when the confirmation just never came back. The next reasoning step builds on that false belief. Every subsequent decision in that session is now compromised.
The fix:
- Attach idempotency keys to every tool call with a side effect
- Hash the inputs, store the result, return the stored result on retry
- Use bounded retries with exponential backoff
- When retries are exhausted, route to a dead letter queue — not silent failure
The implementation isn't complicated. What's hard is remembering to do it for every side-effecting tool call, including the ones that seem harmless.
Standard 4: Irreversible Actions Need a Human Gate
Agents are fast and autonomous. That's exactly why an unchecked agent can cause significant damage before anyone notices.
The answer isn't to make agents slower across the board. It's to identify actions that cannot be easily undone and gate those explicitly.
Escalate to a human before:
- Deleting or overwriting records
- Sending any external communication
- Committing a financial transaction
- Touching anything in production that can't be rolled back
- Requesting resources or permissions outside the original task scope
- Failing the same operation more than N times in a row
That checkpoint costs five seconds. What it prevents is a class of incident where you spend days reconstructing what happened.
The temptation is to automate past these checkpoints once you "trust the system." Resist that until you have enough production history to know — specifically — which failure categories have never occurred. "It usually gets it right" is not a safety argument for an irreversible operation.
Standard 5: Observability Is What Makes Everything Else Fixable
You will ship a bug. Something will behave unexpectedly. The question is whether you can figure out what happened.
At minimum, log:
- Every tool call with inputs and outputs
- Token usage per step
- Cost per task
- Trace IDs across every step
- Escalation events and boundary breach attempts
But raw logs aren't enough.
What you need are execution traces — the full sequence of decisions the agent made, what it observed at each step, and what it called as a result. Without a trace, when a user reports a wrong output, you're guessing. With a trace, you replay the exact path and find the exact step where it broke.
Observability also serves as your cost control. Agent costs in multi-step loops don't scale linearly. Context accumulates. Sub-agent responses feed back into the orchestrator. A workflow that costs cents in testing can cost dollars at production scale.
Track:
- Token consumption per step and per run
- Cost per workflow type per day
- Sudden spikes — they indicate regressions, not noise
And critically: alerts without enforcement are notifications, not controls. A notification nobody sees during off-hours does nothing. Build hard stops — if cost crosses a threshold, the agent pauses and waits for human authorization.
Standard 6: Permissions Follow Least Privilege
Agents accumulate permissions gradually.
The model needs to read a file, so you give it filesystem access. It needs to call an API, so you give it the key. Over time the agent has access to everything, and the scope of potential failure grows with it.
Every agent role should have:
- Read-only access when it only needs to read
- Write access scoped to the specific resources it legitimately modifies
- No access to systems it has no business reason to touch
- Child agents/sub-pipelines that inherit only what they need — not the parent's full permissions
This matters for failure containment as much as security. When an agent has broad permissions and something goes wrong, the blast radius is large. When permissions are scoped, the failure stays contained to what that agent was authorized to touch.
The incident is still bad. It is not catastrophic.
The Standard Nobody Writes Down
The gap between a POC and a production agent is not about adding more features.
It's about adding the infrastructure that keeps the agent honest when things go sideways.
Every standard above is, at root, the same idea: don't assume the agent will always behave the way it did in testing. Design for the cases where it doesn't. Make failures contained, visible, recoverable, and debuggable.
A demo agent is a single happy path.
A production agent is the same happy path — plus everything that can go wrong with it.
The teams that ship reliable agentic systems aren't the ones with the smartest prompts. They're the ones who treated the surrounding infrastructure with the same seriousness they gave the model.
Build that infrastructure before you need it. By the time you need it, it's too late to build it cleanly.
Building AI agents and want to swap notes? Find me on @akashdotkeras or MaxPooling.dev where I share what I learn while building these systems.